

省心/省钱的全程服务
一站式服务体系 保证满足您的各种服务需求
免费代办公司注册
![]()
省心/省钱的全程服务
一站式服务体系 保证满足您的各种服务需求
免费代办公司注册
![]()
注册仅需三大步骤

高级顾问为您把关,用户持续增长中...
所以选择很重要
¥ 0.00元注册费
找其他代办公司:¥500-1500元
![]() 免费热线
免费热线
400-000-8888
专业客服高响应机制随时为您服务
真正极简 快捷流程
综合化管理 只需三步 完成注册

1-2工作日
核名
3-5工作日
提交文件
3-5工作日
领取营业执照
1-3工作日
刻章/银行开户
选择我们 一劳永逸
省钱/省心/省时/省事
告别繁琐工序及时间耗费
不再担心违法陷阱
最大化利用您的每一分钱
跑来跑去浪费无谓的时间
总有你考虑不到的方面
去不熟悉的部门时间利用率低
| 我们只收政府规定的费用和刻章费,免服务费 |
省钱 |
|
| 我们全程代办,让您放心 |
省心 |
|
| 精通办理流程及资料准备,专门渠道专人代办,最快只需3天 |
省时 |
|
| 注册公司是复杂的过程,我们有专业运营团队,简单快速 |
省事 |

400-000-8888
我们的优势
实力说明一切
| 项目 | 名称 | 财务之家 | 其他代理公司 |
|---|---|---|---|
| 服务速度 | 名称查询速度 | 3个小时内 | 无法保证时效 |
| 工商核名申请 | 保证当天上报 | 极少做到 | |
| 售后服务 | 一对一顾问 | 提供,对公司进行整合式管理 | 无 |
| 公司信息数据归档 | 提供,对公司进行整合式管理 | 无 | |
| 增值服务 | 网络营销指导 | 提供,一站式服务 | 极少提供 |
| 当月回访 | 提供,让您的成长变 得简单 | 无 | |
| 网站建设优惠套餐 | 您只需购买好空间域名,免费建站 | 无 | |
| 国家优惠政通知 | 提供,让您第一时间享受利好政策 | 极少做到 | |
| 提供免费财税咨询 | 提供 | 部分提供 | |
| 可靠性 | 顾问/代理人/财务三重把关 | 最大限度避免漏报、 错报、晚报 | 无 |
| 专用服务器/软件/数据多重备份 | 信息系统安全可靠 | 无 | |
| 严密的保密制度 | 制度严密、公司稳定 、人员流动性低 | 极少做到 |
只需一个电话
400-000-8888
金杯银杯不如客户口碑



新闻动态
文心一言是百度研发的 人工智能大语言模型产品,能够通过上一句话,预测生成下一段话。 任何人都可以通过输入【指令】和文心一言进行对话互动、提出问题或要求,让文心一言高效地帮助人们获取信息、知识和灵感。
指令(prompt)其实就是文字,它可以是你向文心一言提的问题(如: 帮我解释一下什么是芯片 ),可以是你希望文心一言帮你完成的任务(如: 帮我写一首诗/画一幅画 )
文心一言网页版地址:https://yiyan.baidu.com

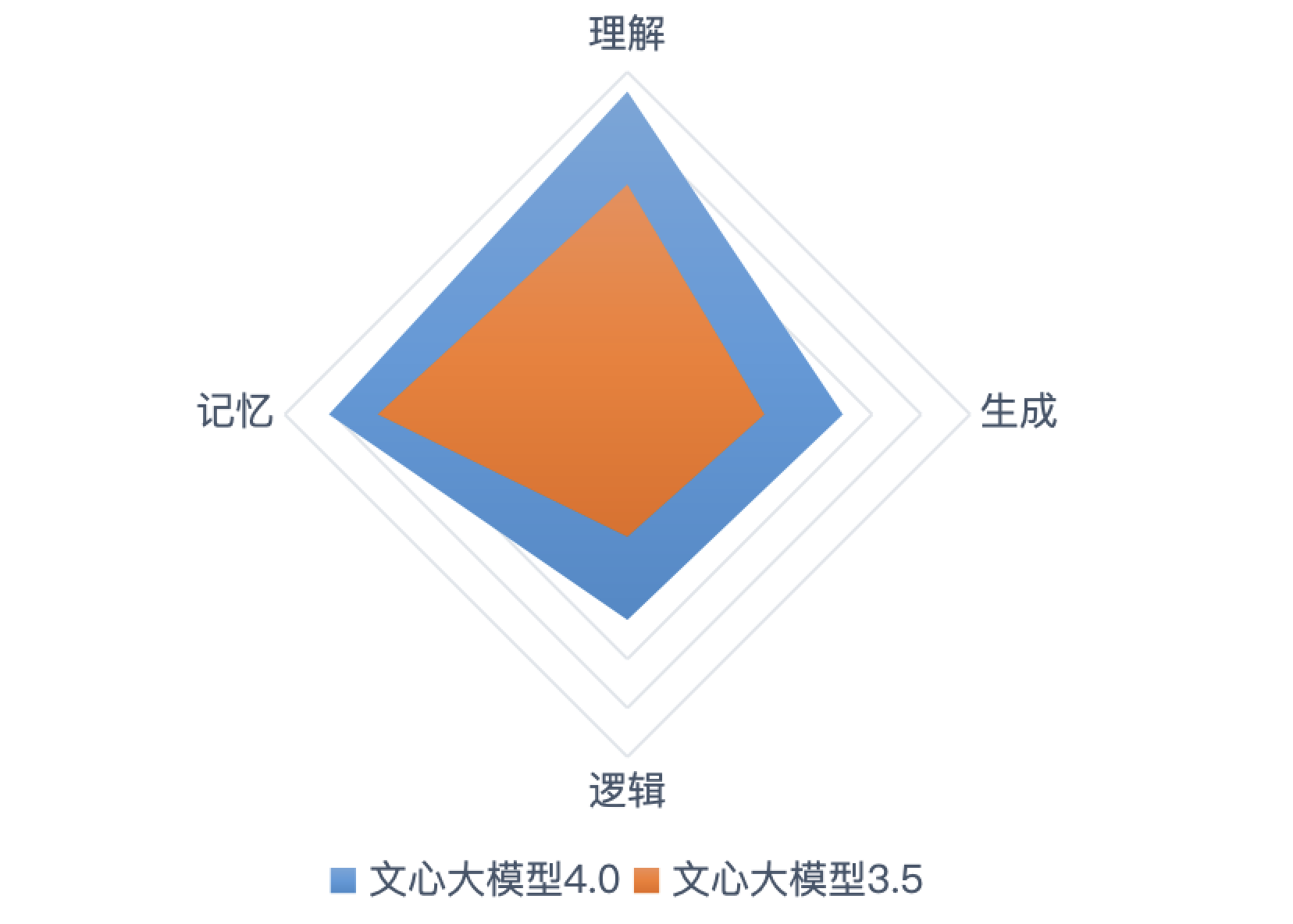
文心一言由文心大模型驱动,具备理解、生成、逻辑、记忆四大基础能力。当前文心大模型已升级至4.0版本,能够帮助你轻松搞定各类复杂任务。
理解能力: 听得懂潜台词、复杂句式、专业术语,今天,人类说的每一句话,它大概率都能听懂!
生成能力: 快速生成文本、代码、图片、图表、视频,今天,人类目光所致的所有内容,它几乎都能生成!
逻辑能力: 复杂的逻辑难题、困难的数学计算、重要的职业/生活决策统统能帮你解决,情商智商双商在线!
记忆能力: 不仅有高性能,更有好记性。N轮对话过后,你话里的重点,它总会记得,帮你步步精进,解决复杂任务!
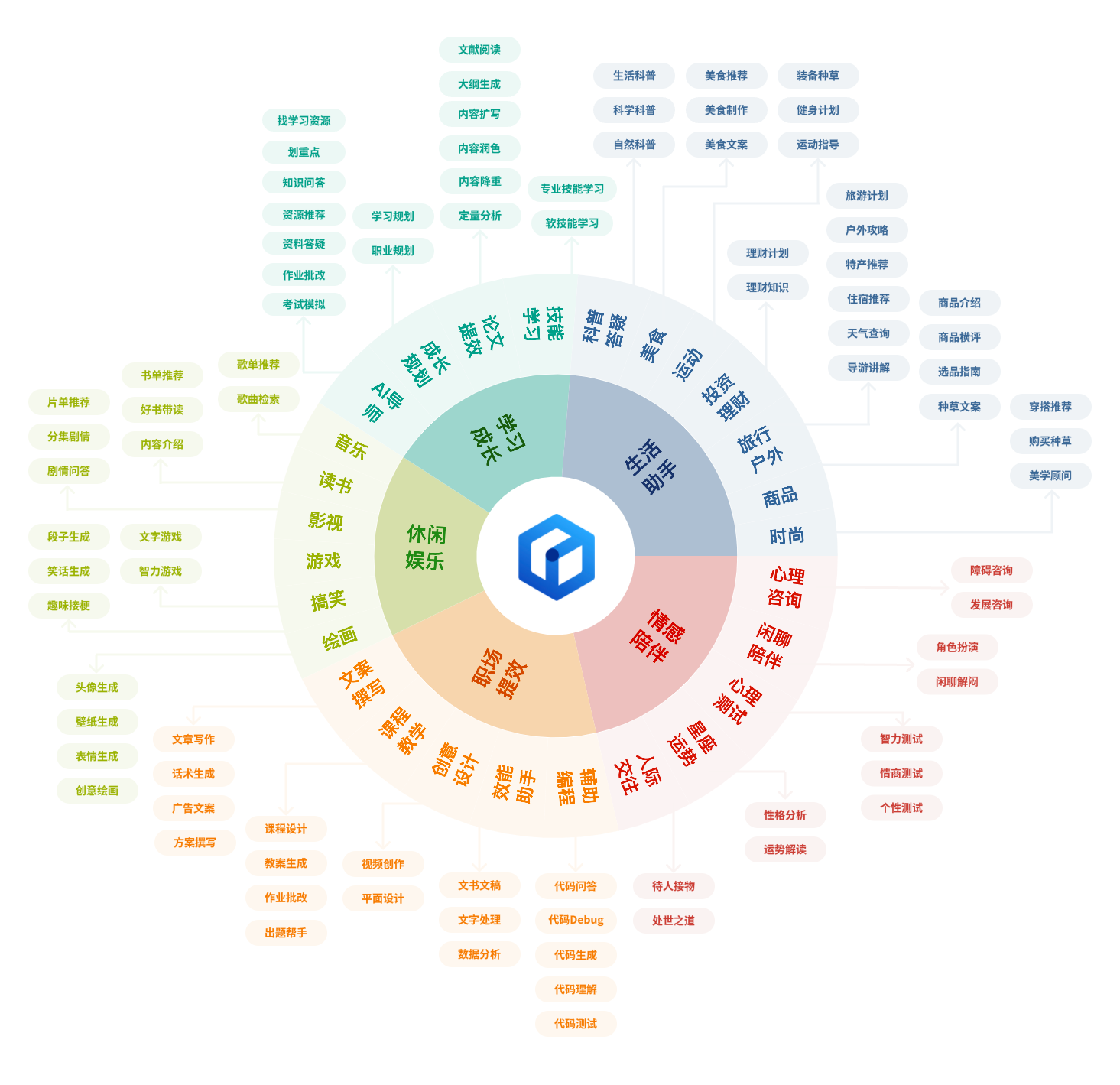
文心一言是你工作、学习、生活中省时提效的好帮手;是你闲暇时刻娱乐打趣的好伙伴;也是你需要倾诉陪伴时的好朋友。在你人生旅途经历的每个阶段、面对的各种场景中,文心一言7*24小时在线,伴你左右。
在纷繁的社交网络中,你是不是会在某一时刻感到孤独?在复杂的人际关系中,你是不是会在一个瞬间感到疲惫?面对工作和生活中的各种压力和挑战,别再焦虑无助了!试试运用指令公式让善良真诚又富有智慧的文心一言化作情感树洞陪伴你、温暖你、帮助你。
无论是情感困扰需要咨询还是个人心事需要倾诉,又或是扮演平日里的闲聊伙伴,甚至是来一次性格心理测试,这些文心一言都通通在行。
如果你在亲密关系中是一位“小白”,经常不知道该如何在关系中进行有效交流
就让文心一言帮你出谋划策,促进你和亲密伙伴更深层次的情感连接和互动理解。
在文心一言对话框输入:
你是一名【感情咨询专家】。我的女朋友即将前往异地工作,我们交流和见面的时间都会变少,我很担心。请你分享一些情感支持方法和实施建议,让我在爱情中能更好应对这一变化,让我们感情更加牢固。

保密事项范围是确定、变更和解除国家秘密事项的具体标准和依据。
依据《保密法》第15条第1款规定,国家秘密及其密级的具体范围(即保密事项范围),由国家保密行政管理部门单独或者会同有关中央国家机关规定。该条款授权国家保密行政管理部门或者会同有关中央国家机关,制定、修订、解释保密事项范围。在具体定密工作中,承办人需对照保密事项范围提出国家秘密确定、变更和解除的具体意见,再由定密责任人审核批准。保密事项范围为定密工作提供了明确的规范和指引,有助于准确判定国家秘密的相关事宜,是加强定密管理的基础所在。
 智能文档翻译
智能文档翻译 百度翻译网页版
百度翻译网页版


 人工翻译
人工翻译 百度翻译开放平台
百度翻译开放平台 百度AI同传
百度AI同传 抗击新冠肺炎公益行动
抗击新冠肺炎公益行动我们的合作伙伴
数百家优秀企业已经选择了我们

您可能还需要的服务
一站式服务 意在满足您的各项需求
申请一般纳税人
汇算清缴报告
我们做的不是代办 而是对行业的改变
财务之家拥有具有客户第一意识和协同精神的专业代理 人团队;公司核名成功率远远高于行业平均水平。
注册经验领先,长期与国内多家知名的会计事务所、税 务事务所保持着战略合作伙伴关系。
所有名字当天查询,当天核准申请;提供一对一的顾问 定制服务。
400-000-8888






